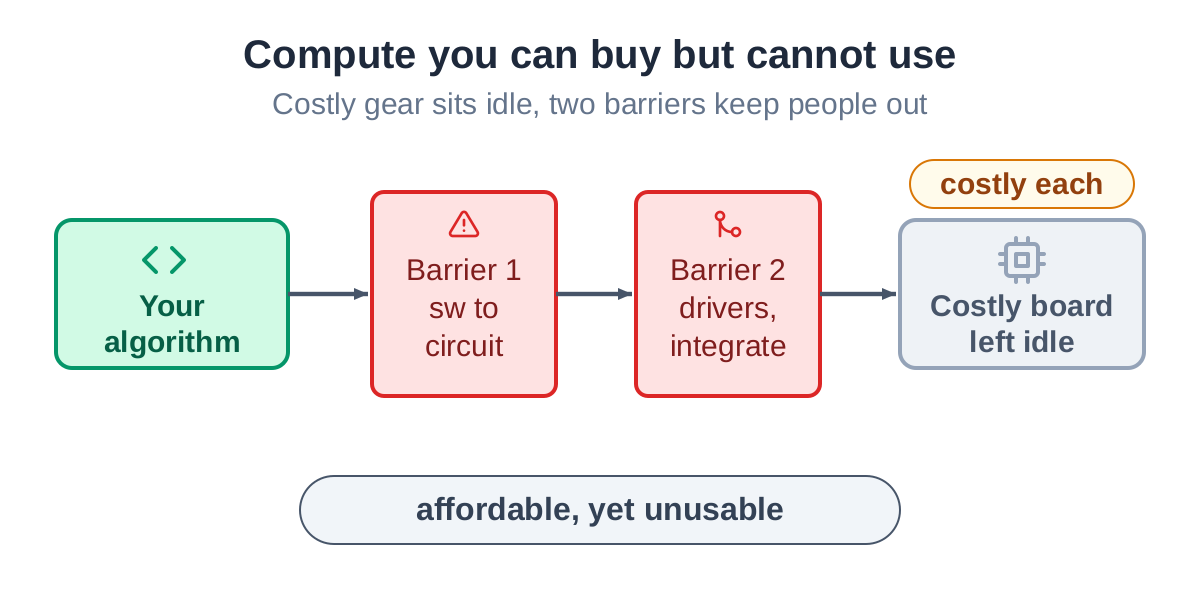
A research lab or a product team buys an SDR or an FPGA board that costs as much as a car. They run a few data captures, and the board goes on the shelf. The hardware is capable of far more than simple capture and playback. The reason it sits idle is that doing real custom work on it is genuinely hard.
The compute is bought, but it sits idle
The barrier has two parts, and a project needs to clear both.
The first is turning a software algorithm into efficient hardware. A CPU runs one instruction after another; an FPGA runs hundreds of operations in the same clock tick. The same algorithm written merely to run, and written to run fast and small, are two different designs, and the distance between them is a specialist skill.
The second is getting that hardware to actually run on the board: the interfaces, the data movement, the drivers, the application around it. It takes someone fluent in both the low-level fabric and the high-level software, and when something breaks it is hard to tell which layer broke.
Those two barriers together keep expensive hardware underused, and keep the pool of people willing to learn the craft shrinking.
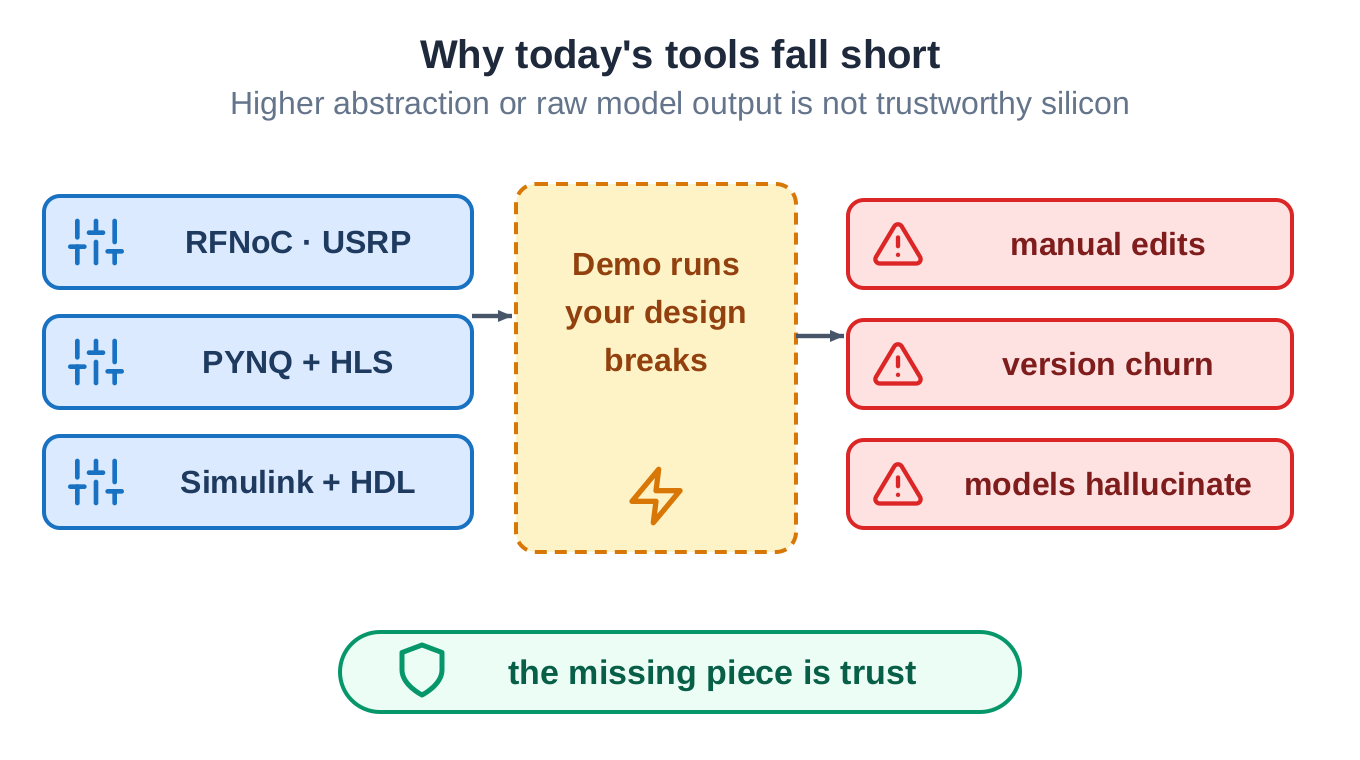
Why today's tools fall short
Vendors have built tools to lower the barrier. USRP has RFNoC. AMD and Xilinx have PYNQ with high-level synthesis. MathWorks has Simulink with HDL Coder. They help, and the common experience is still the same: the demo runs, and the moment you swap in your own design, problems appear. The flow needs a lot of manual file and parameter editing, and the tool versions move quickly.
Raising the level of abstraction does not close the gap by itself. High-level synthesis is well documented to carry a productivity-versus-performance gap: choosing the right pragmas and restructuring code to be hardware-friendly still takes deep hardware experience, and a real frequency gap to hand-written RTL remains.
The newer path, letting a large language model write the Verilog directly, has a problem it cannot escape. The model produces hardware that looks reasonable and is functionally wrong. On the standard Verilog benchmarks, functional correctness has climbed from roughly 60% to around 90% with the best methods, and the remainder is still wrong. No method removes it entirely. The missing piece is trust.
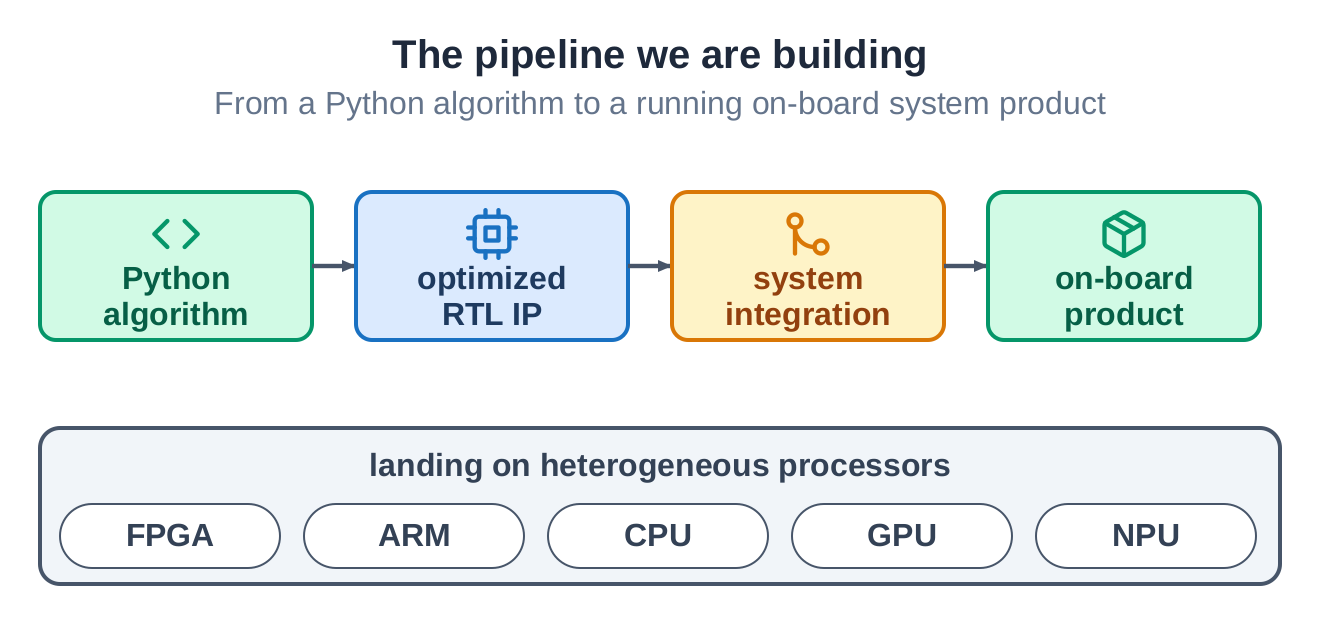
What we are building
We are building an AI-driven automation toolset that carries a Python algorithm through optimized, verified RTL IP, to a running, system-integrated product on real hardware. FPGA is not the only target. The same flow reaches the host CPU, the embedded ARM, and emerging GPU and NPU accelerators, working together.
The pieces are in place. The flow generates optimized RTL IP from a Python algorithm, and we have done the same from MATLAB through high-level synthesis C. It closes the timing and minimizes the resources, the parts of FPGA work no one enjoys. And it carries the design onto the board: automated system integration, pre- and post-silicon simulation, and on-device testing.
Strung together, that is one pipeline from a Python algorithm to a product that runs on the board. The algorithm is at the front, the working system is at the end, and the hard, tedious middle is handled by the framework and the AI.
Making AI-built hardware trustworthy
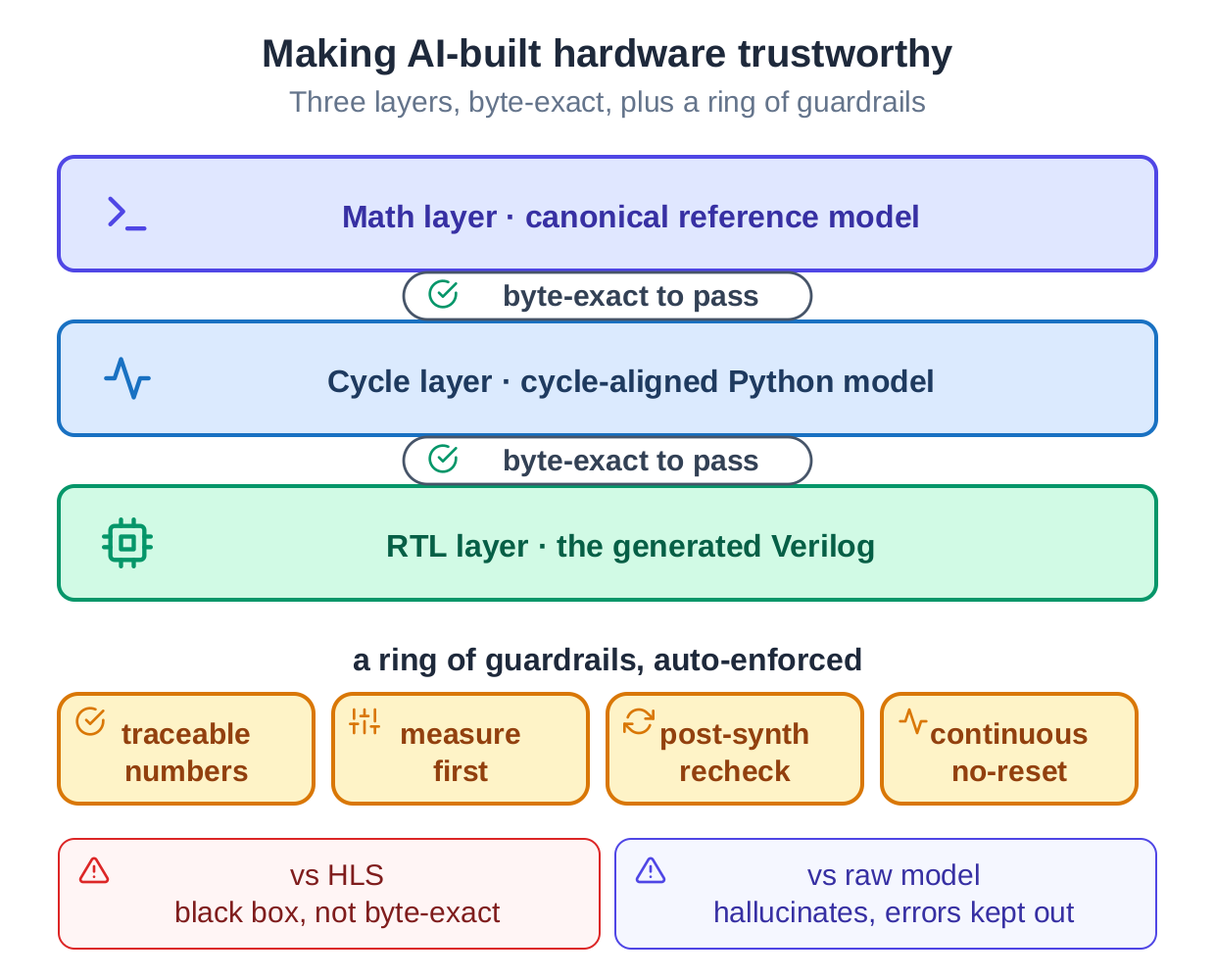
This is the core of it. Getting an AI to write hardware is not the difficult part. Getting it to write hardware you can trust is. Our answer is a three-layer chain, where each layer is the reference for the one below it, plus a ring of guardrails.
The three layers are math, cycle, and circuit. A canonical mathematical model, validated against the governing standard, is the arbiter of right and wrong. A cycle-accurate Python model mirrors the hardware tick by tick. The Verilog RTL is translated from that model and checked against it. The vectors that do the checking are generated by the math layer, never written by hand. Three layers, byte-exact, or it does not pass.
That is the difference from high-level synthesis, a black box with no bit-exact guarantee, and from a raw model, whose plausible-but-wrong output never clears the byte-exact gate and so never reaches the next layer. Around the chain sit guardrails, each enforced by an automatic check: every number traces to a current tool report, measurement comes before any rewrite, feedback paths are re-checked on the synthesized netlist before silicon, and continuous designs are validated back to back with no reset.
Trustworthy AI hardware does not come from the model being clever. It comes from every step being checked to the bit against an independent reference.
Proven on a Wi-Fi receiver
The method is proven on a real system. We generated a complete 802.11a Wi-Fi receiver and brought it up on the ADALM-Pluto, whose chip is an entry-level Zynq-7010. The receiver is too large to sit on that small chip alongside the radio's own interface logic, so it runs split across three tiers: the rate-critical front end on the FPGA fabric, data movement on the embedded ARM, and the decode back end on the host. Every tier is checked bit-exact against the same reference.
Run over the air, the receiver recovers every one of the eight 802.11a data rates, from BPSK to 64-QAM, bit for bit.
The full walk-through, with the receiver signal chain, the measured clocks and resource numbers, and the over-the-air results, is in the case study: An AI-generated Wi-Fi receiver, verified bit for bit.
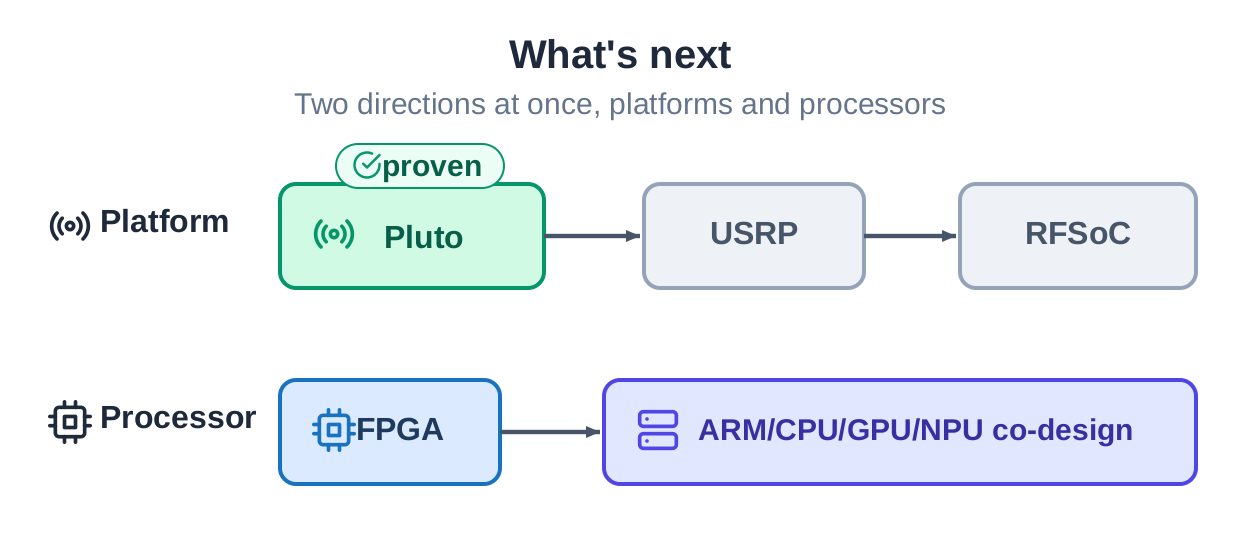
What comes next
Two directions. One is platforms: from the ADALM-Pluto to larger USRP and RFSoC systems. The other is processors: from the FPGA out to the CPU, ARM, GPU, and NPU working together. The aim is the same throughout. Turn the path from an algorithm to silicon into an automation pipeline you can trust, so the compute people already own gets used instead of sitting idle.