容错量子计算机每一轮测量都要读出一个错误信号,并在下一轮到来之前推断出最可能的物理错误。 对超导量子比特来说,这个预算大约是每轮一微秒。译码器因此是一台硬实时的经典机器,而不是一个离线 求解器,也是横在今天实验室机器与一台真正可用的机器之间的关键之一。
这是用我们的算法到硬件流程,从算法一路做到布线后硅片,复刻 IBM 面向 [[144,12,12]] gross 码的 Relay-BP 译码器的全过程。先把诚实的结论摆出来:它落在与公开参考实现相同的硅片包络上,真正的贡献 是一张「哪些优化有效」的清晰地图,以及那一个真正有效的算法杠杆。
译码器到底在做什么
普通的置信传播是经典纠错译码的主力:每个校验把已知信息告诉每个错误位,各位更新自己的置信度, 几轮之后最可能的错误图样就浮现出来。但它在量子码上会卡住,码的结构会制造出对称的陷阱,让置信度 来回振荡、永不收敛。Relay-BP 加了三个想法来打破这种对称。
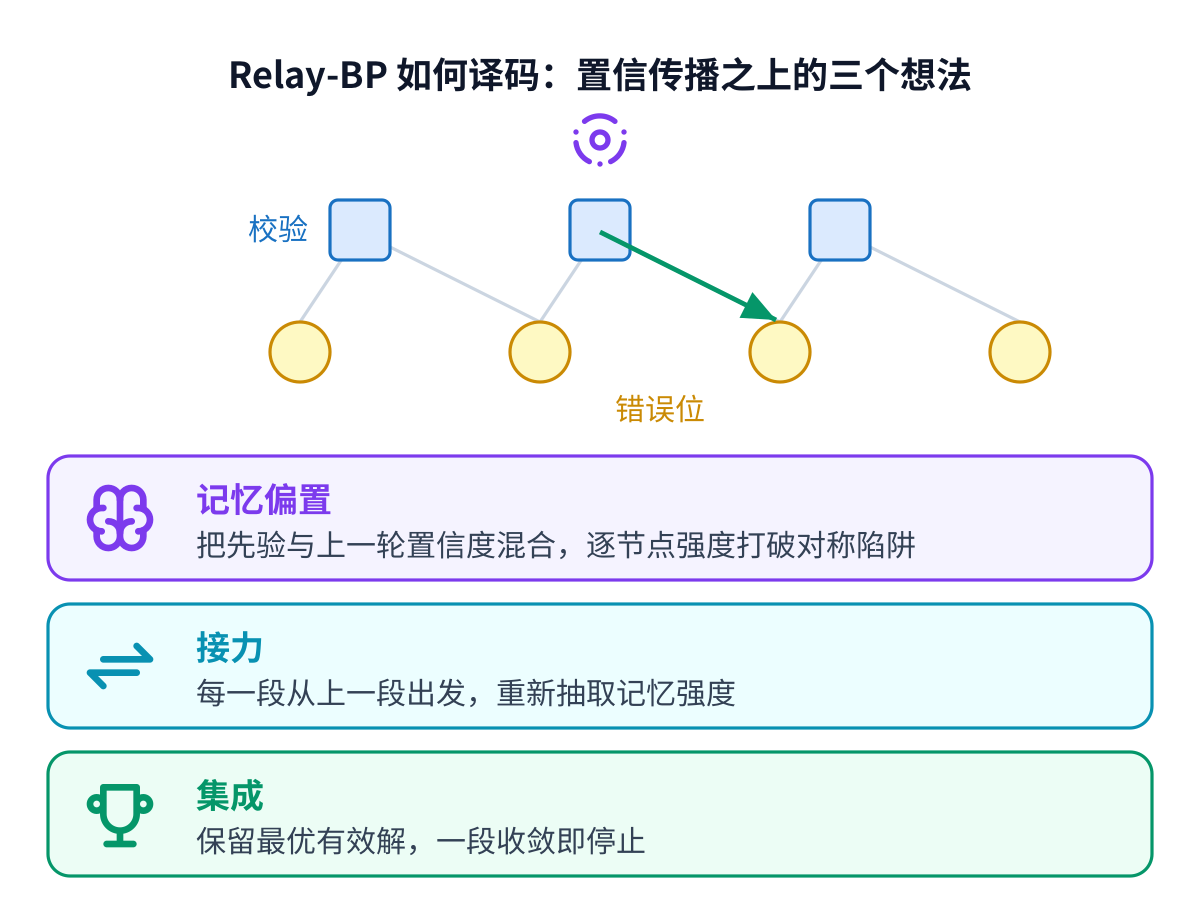
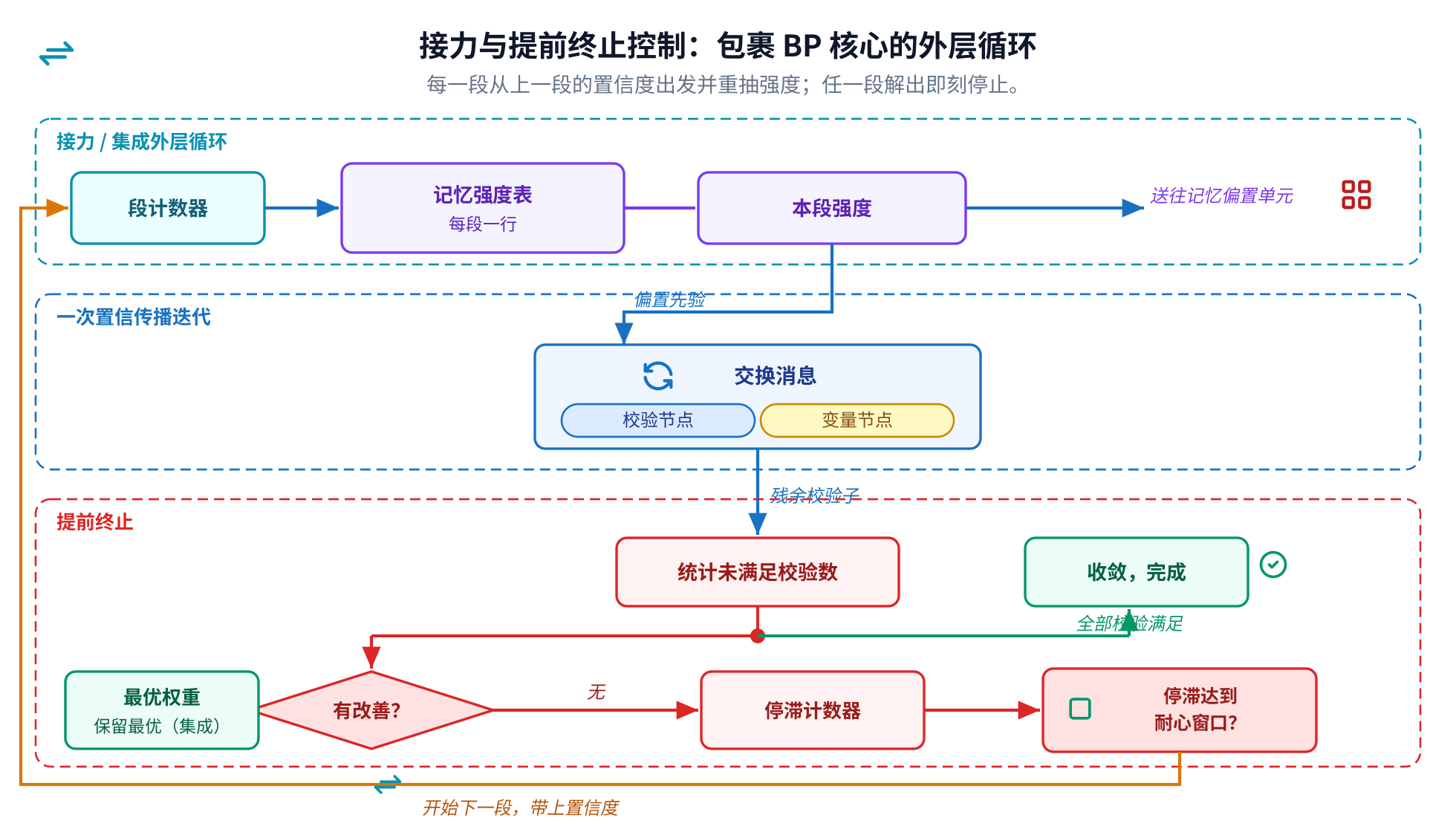
记忆偏置把每个位的先验与它上一轮的置信度按逐节点强度混合,这个强度允许为负。接力把整个译码分成 多段,每一段从上一段的置信度出发、并重新抽取强度,等于换一条新路径去找解。集成保留最低权重的有效解, 并在任一段收敛的瞬间停止。在 gross 码上,这套组合的逻辑错误率比通用后处理译码器大约低一个数量级 (IBM,arXiv:2506.01779)。
把这台机器摊开来看
后面所有的内容,本质上都只是下面四个小单元在码图上反复铺开的结果。先在电路层看清它们是值得的, 因为代价、那堵墙、以及最后的收益,都指回这四者之一。
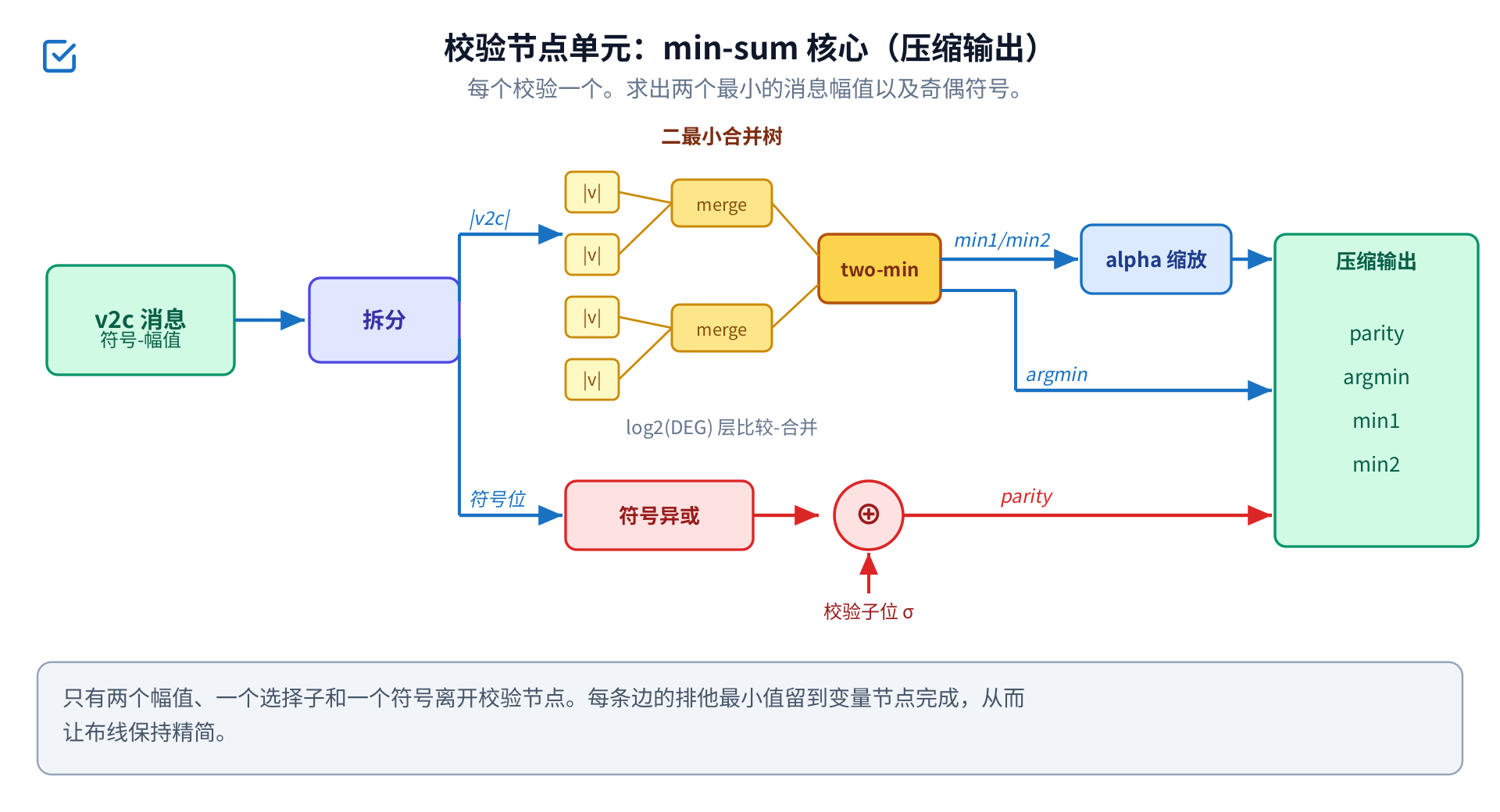
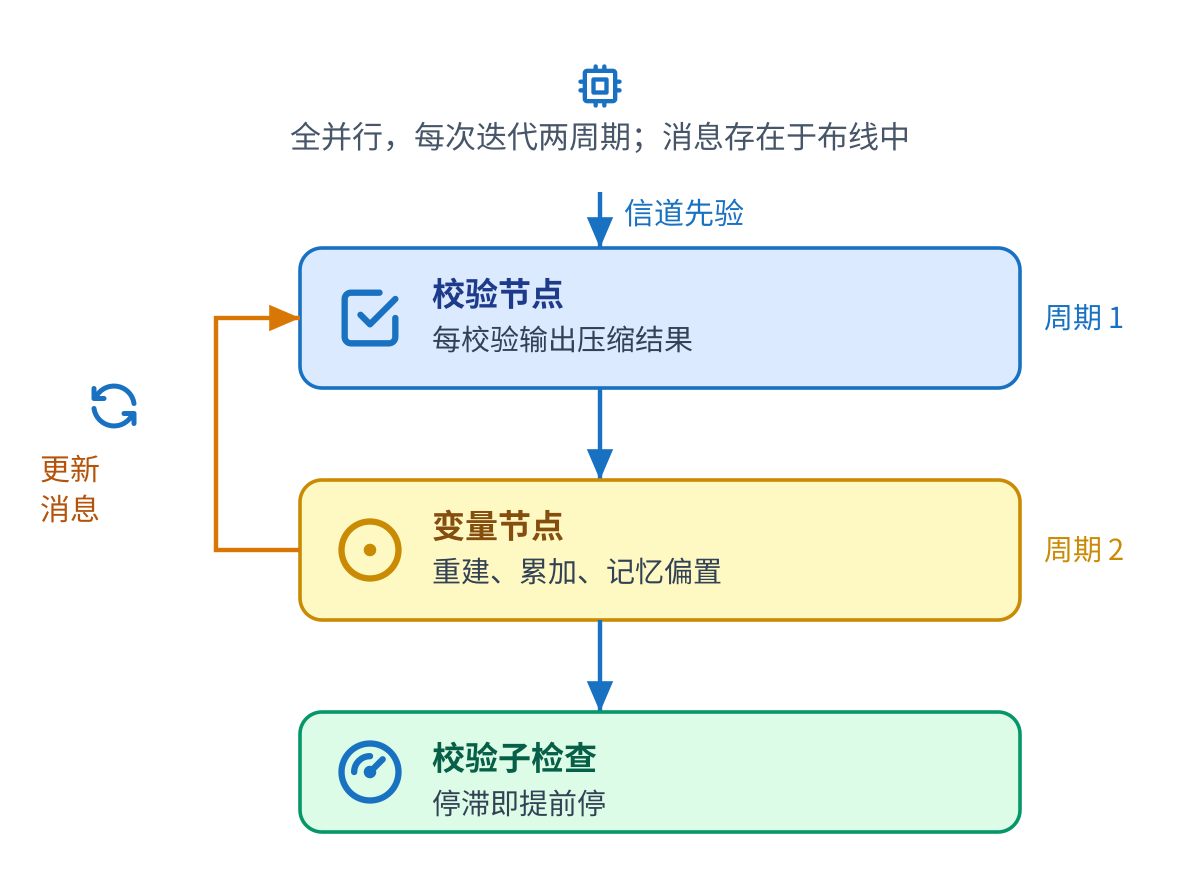
校验单元每个校验一个。它求出进来的两个最小幅值以及最小值所在的位置,把符号合并成 一个奇偶位,只送出这个压缩后的元组。每条边的细节留到位侧再算,这正是输出总线得以精简、布线得以负担 的原因。
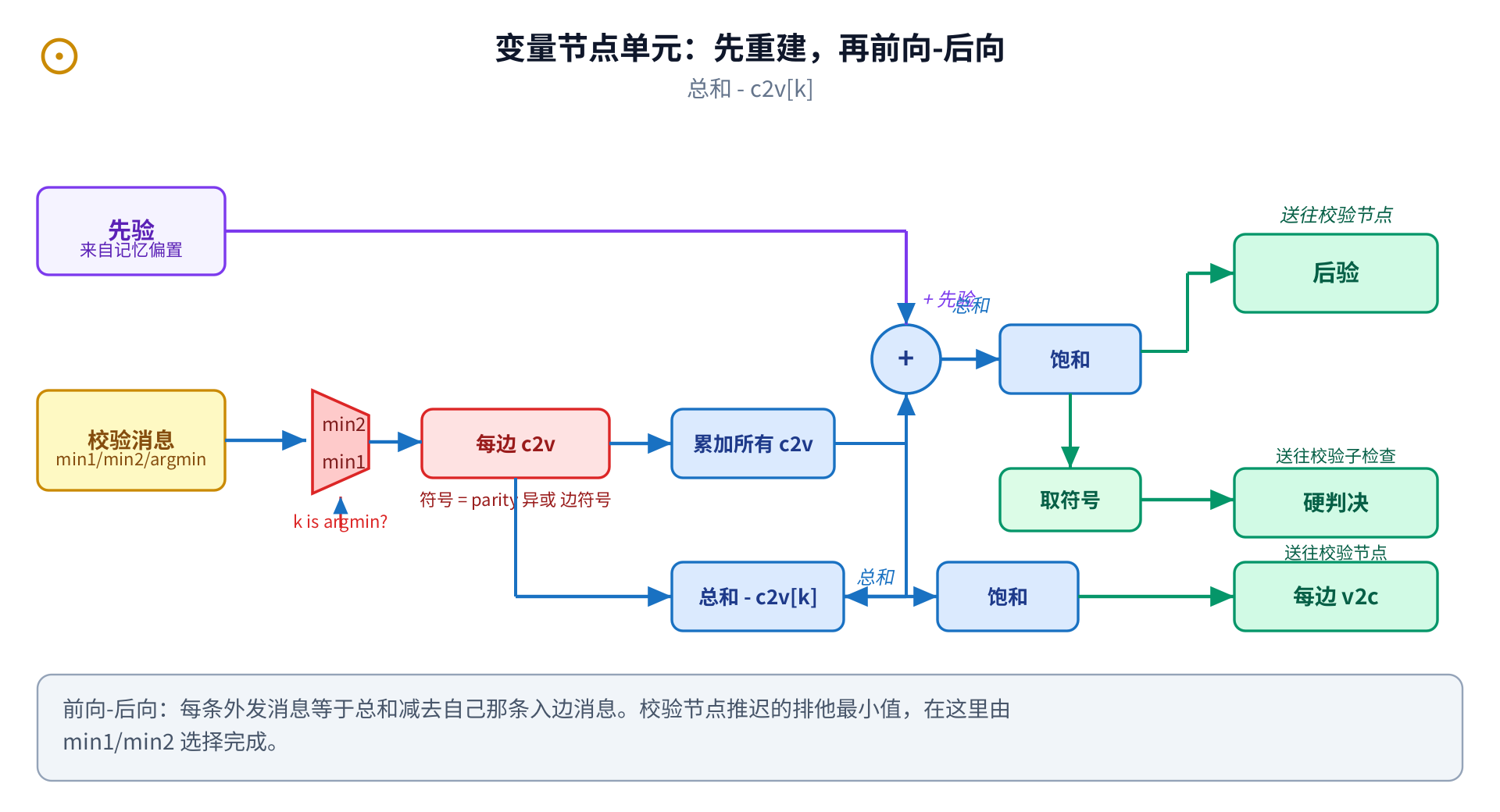
位单元每个错误位一个。一个小选择器从压缩元组里重建每条进来的消息,该位把它们与 先验相加并饱和,再用前后向相减给出每条出去的消息和当前硬判决。这个重建步骤,正是偿还校验单元压缩的 那一步。
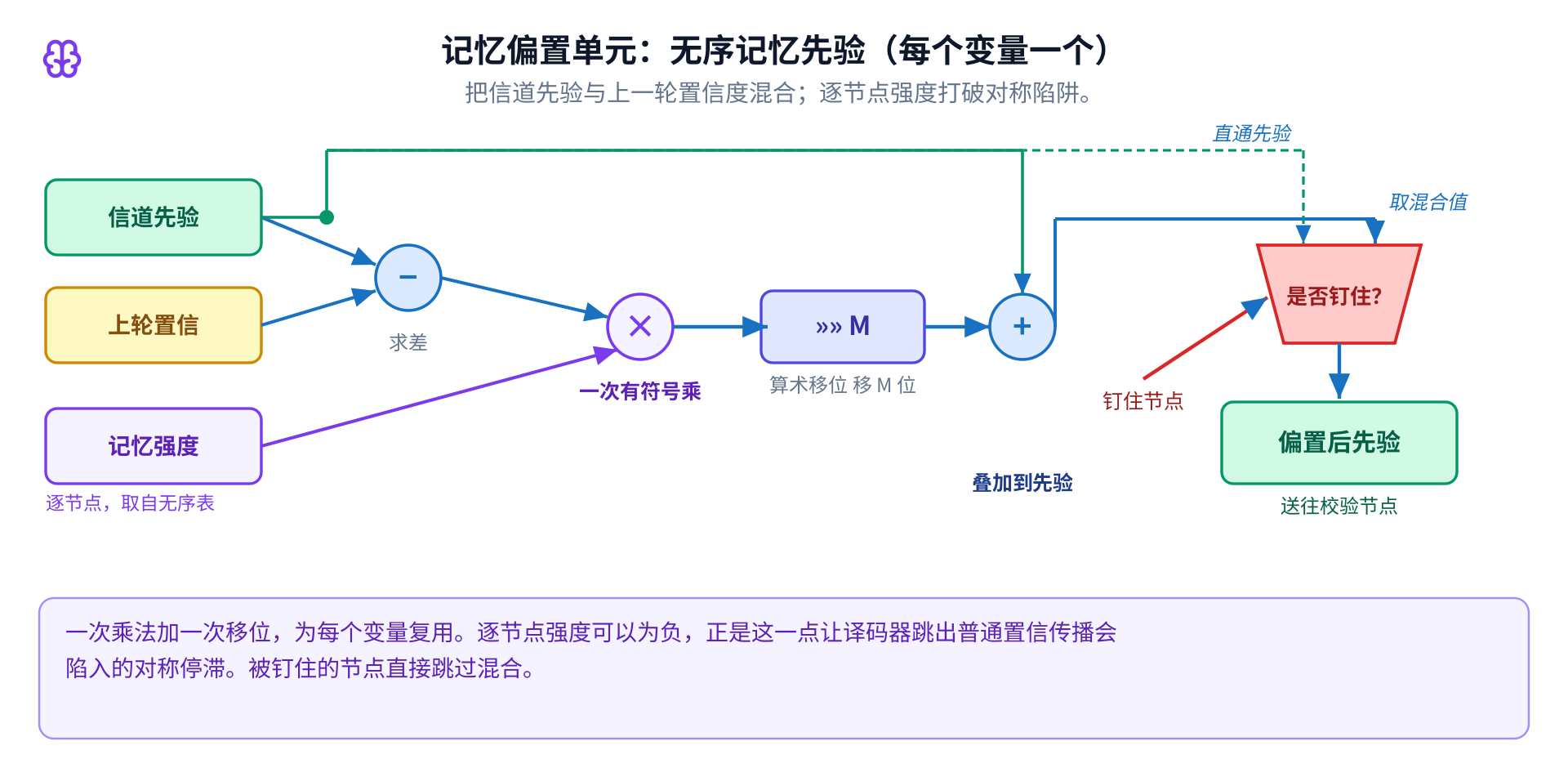
记忆偏置单元是 Relay-BP 想法在硬件里的样子,每个位一个。它用一次乘法和一次移位把 先验与上一轮置信度混合,被钉住的位则直接透传先验。逐节点强度可以为负,正是这一点让一次译码跳出对称 停滞。
控制包在循环外面。段计数器索引一张逐段强度表,喂给记忆偏置单元,置信度从一段带到 下一段。一个未满足校验数的统计驱动两个寄存器:一个记住迄今最优的尝试,另一个统计进展停滞了多久。 错误信号清零则立刻结束译码。那唯一真正有效的优化,就住在这里。
硬件为何如此之大,时钟又花在哪
参考的硅片译码器是全并行的:每个图节点一个计算单元,每条边一根线,一整轮只用两个时钟周期。它没有 集中的消息存储,消息就活在布线本身里,这也是为什么整个设计由布线而非逻辑主导。
我们实测了一个可综合的距离 5 版本(gross 码的忠实代理),并与公开的 gross 码硅片实现对比。每条关键 路径大约 70% 是跨芯片搬运消息的线延迟,这是这类码图固有的性质。时钟受限于布线,而不是逻辑。这正是 结果落在参考包络上、而非超过它的原因:布线就是那堵墙,对任何做全并行的人都是同一堵墙。

什么改善了延迟,什么没有
译码延迟等于迭代次数乘以每次迭代周期数再除以时钟。当时钟被布线钉死之后,真正能改善延迟的手段其实 很少,而且有几个看似聪明的方向反而帮了倒忙。

选对数据位宽把迭代次数降到四分之一,是一个实打实的胜利:位宽更小虽省面积,却收敛慢得多,省下的 面积是个延迟陷阱。对比较树做流水提升了时钟,却每次迭代多花一个周期,单次译码延迟反而更差。把计算时分 复用满足不了一微秒的预算。把布局压缩到更少的芯片分区,用跨区延迟换来了拥塞、时序退化。真正有效的杠杆 在算法层:一次尝试一旦不再有进展,就立刻结束它。
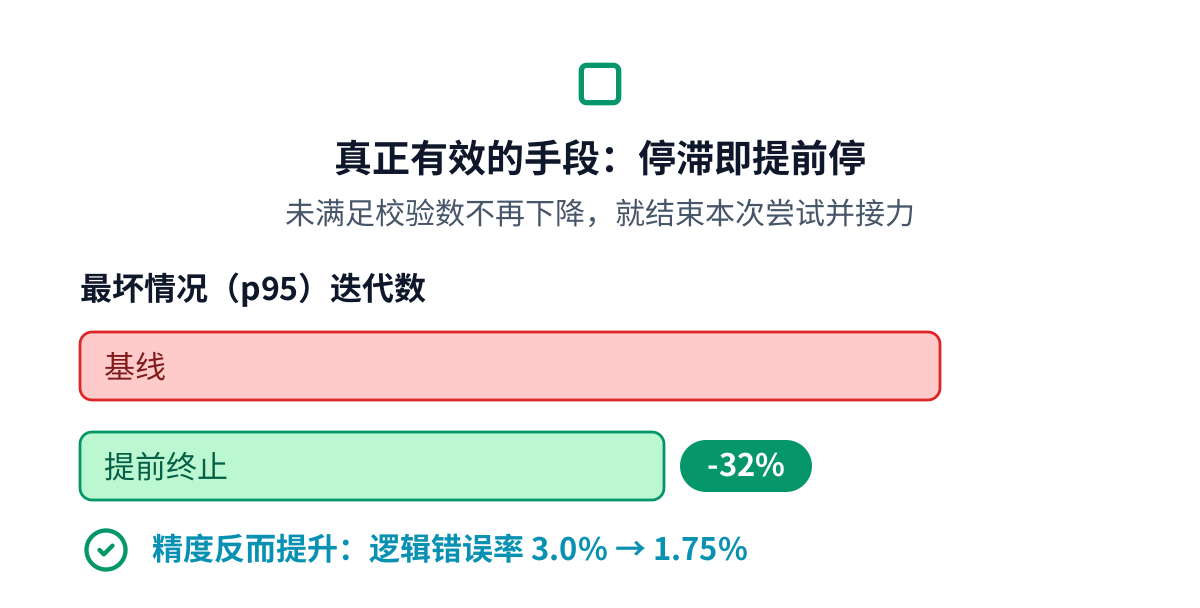
提前终止把最坏情况迭代次数削掉了约 32%,而且精度不降。逻辑错误率不降反升,因为每一次新的接力都在 探索一条通往有效解的新路径。在硬件上它只要统计一下未满足的校验数和一个小计数器,代价约为半个百分点的 面积和几兆赫兹的时钟,对一个延迟优先的译码器是一笔很划算的交易。
这对方法本身意味着什么
这个从「逐层与数学对齐」的模型生成出来的译码器,坐在了 gross 码公开硅片的包络上:同样的时钟区间、 同样的资源量级。它没有更快,因为那堵墙是码图的布线,对任何全并行实现都一样。可迁移的成果是那个循环和 那张诚实的地图:在受布线限制的设计上,时钟是码图的性质,所以该把力气花在更少的迭代或更少的线上,而不是 流水或布局;任何提前停止的策略都要在规模上用逻辑错误率验证,而不是只看收敛。这里每一个数字都追溯到一次 实测,每一层都与下一层逐位对齐。
完整的技术细节(四个单元的电路级微架构、实测的资源与时钟表、以及验证链)见 技术报告。