A soft-decision Viterbi decoder is the forward error correction inside almost every Wi-Fi, LTE and satellite link. The hard part is not the decoding; it is fitting the decoder onto a cheap, small FPGA, or packing many channels onto one device. That is an FPGA resource-optimization problem: spend as few LUTs, flip-flops and block RAMs as the job allows. This is the story of handing that problem to an AI.
The decoder is generated as Verilog from a Python algorithm by our algorithm-to-silicon flow. What follows is the ordinary engineering loop that AI then ran on it, the way an FPGA engineer would: read the utilization and timing reports, pick a lever, measure, tell the right fix from the wrong one, back out of dead ends, and prove every change bit-exact.
What the decoder actually does
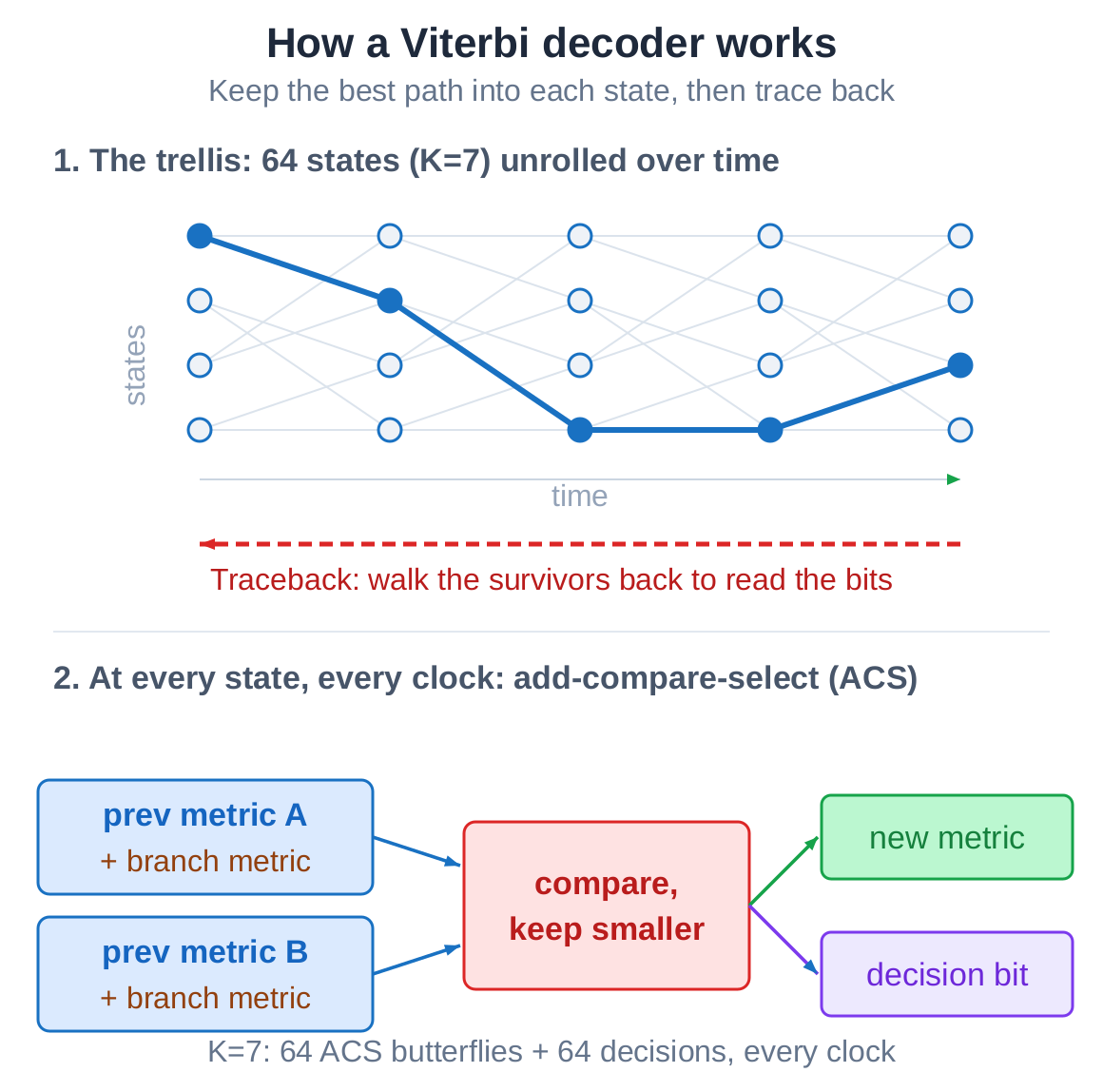
It helps to be concrete first, otherwise neither what is being saved nor why it is hard makes sense. Picture a layered road map: each layer has a handful of junctions, and you want the lowest-total-cost path from start to finish. At every junction you keep only the best road that arrived there and throw the rest away on the spot. At the end you walk backward along the roads you kept, and the single best path falls out. That is what Viterbi does.
In a radio: a convolutional code adds redundancy to every transmitted bit, and the receiver sees a stream of noisy soft samples. The decoder has to recover, out of that noise, the most likely bit sequence that was actually sent. That is maximum-likelihood decoding.
The road map is called the trellis. Constraint length K=7 means 64 states, 64 junctions. Every clock, each state runs one add-compare-select (ACS): add the branch metric, compare the two incoming paths, keep the survivor, and record which one it kept. One step is 64 ACS butterflies and 64 decisions.
Each step's record of which-one-survived is stored. After a window of about 5×(K-1) steps, the decoder walks back along those survivors from the current best state and reads the decoded bits out one by one. That walk-back is the traceback.
Why efficient hardware is hard
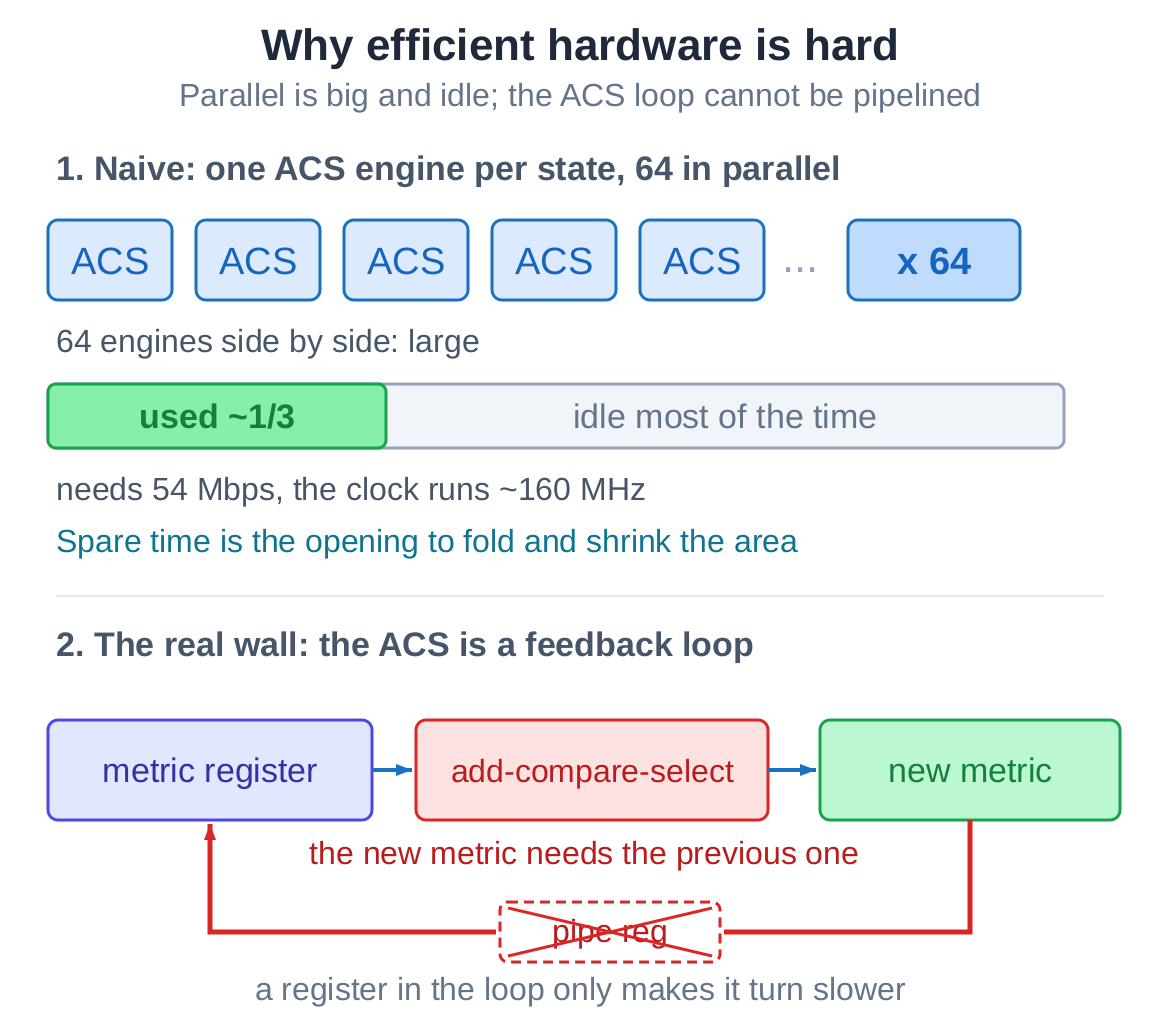
The most direct build gives each of the 64 states its own ACS engine, 64 of them laid out side by side, one step per clock. Fast and simple, but large and wasteful, and idle most of the time: the throughput the application needs is far below the clock the FPGA can run.
The harder wall is in the ACS itself. The new state metric depends on the metric computed the previous clock, which makes it a feedback loop, a recurrence. The trouble with a recurrence is that you cannot shorten a slow path by adding pipeline stages: the next clock needs this clock's result, so inserting a register only makes the loop turn slower. So "folding saves area" and "folding still holds the clock" are two different questions, and that is exactly what makes this hard.
The survivor and traceback memory cost more, and every clock has to read a wide slice of metrics in parallel, so read-port pressure is a real cost too.
So why fold at all? Because the application does not need full speed. 802.11a tops out at 54 Mbps, while a full-rate Viterbi at 160 MHz emits one bit per clock, near 160 Mbps: almost three times more than the standard ever asks for. That spare clock is the opportunity. Spend it time-multiplexing the compute: run one engine over several cycles instead of laying down a fully parallel one, and as long as you stay above 54 Mbps you give back nothing but area. One hard part is left: can you fold without losing the clock.
AI's first lever: folding
Folding is exactly that time-multiplexing: share one add-compare-select engine across several clock cycles instead of building one per trellis state. AI folded the decoder and the area dropped hard: on a low-cost Zynq-7010 the K=7 core fell from 1,918 LUTs to 681 across fold 1 to fold 8, about 65% off.
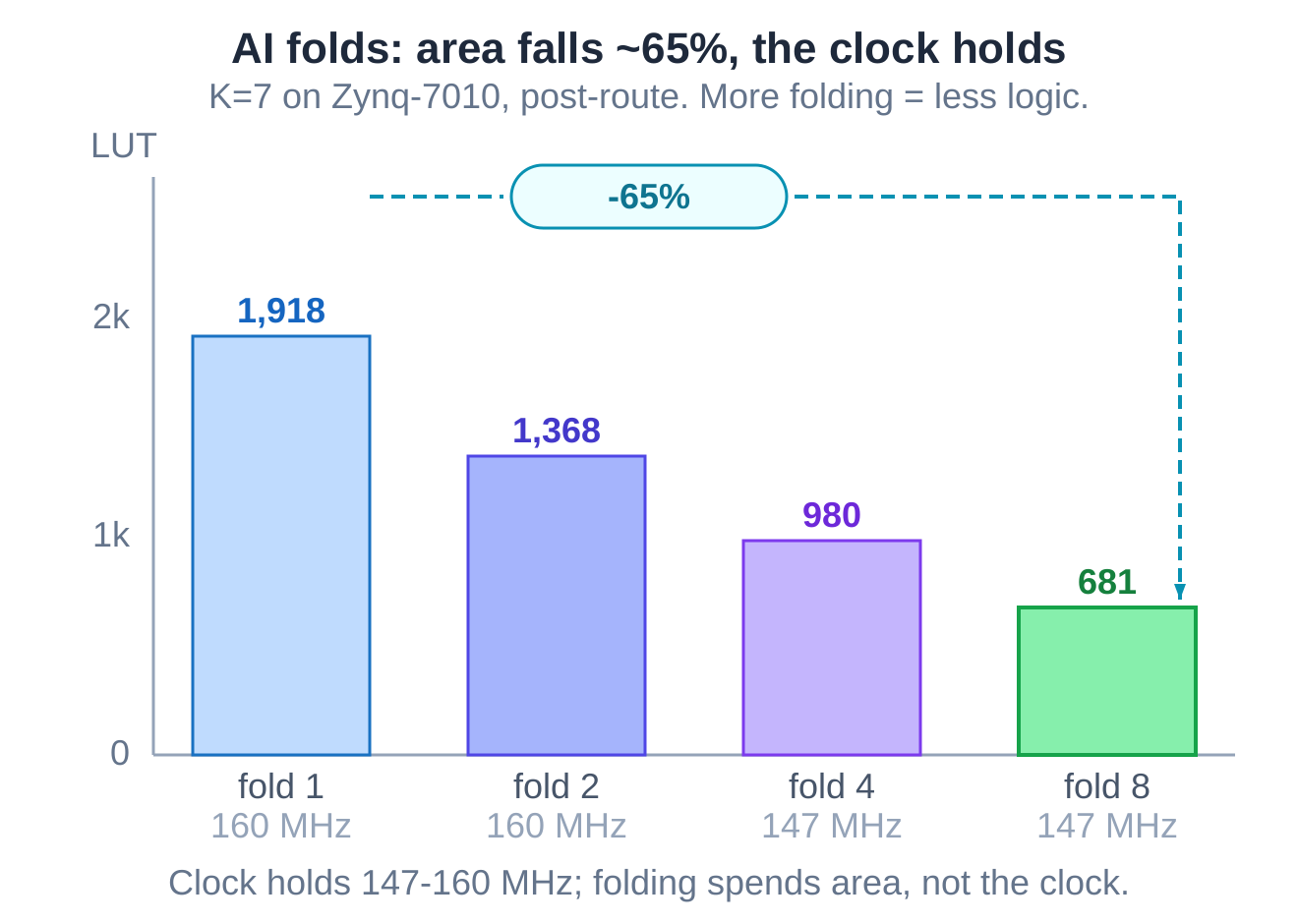
But AI also measured the clock, and it had dropped. AI did not stop there.
AI's diagnosis: folding did not cost the clock
AI read the critical path and pinned the lost clock precisely: it had little to do with folding itself, and everything to do with the read micro-architecture. After folding, each clock has to read a different slice of the score memory, and the obvious way to do that is to index a multiplexer with the phase counter. That phase counter then sits right on the read path into the decoder's feedback loop, and caps the clock.
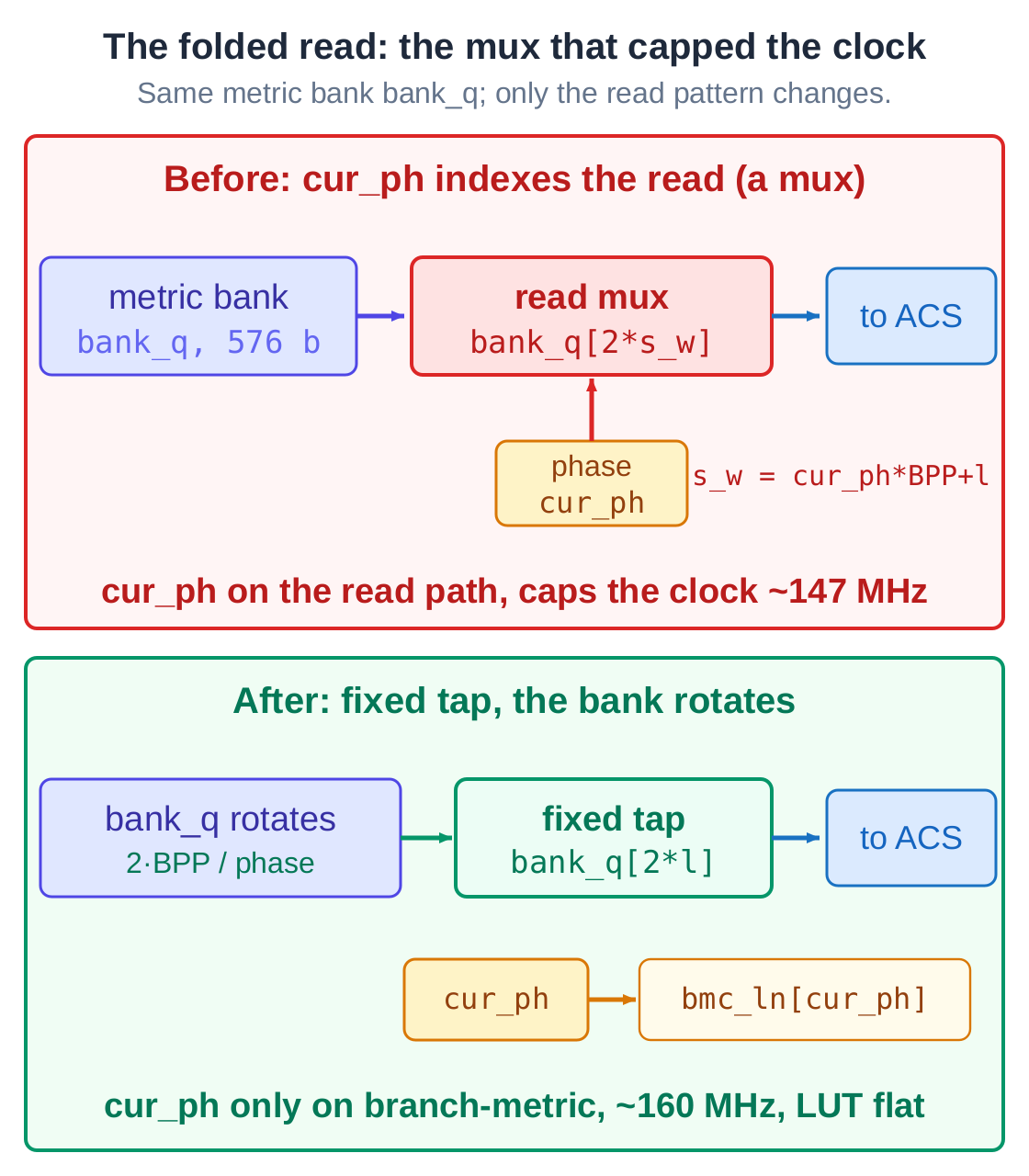
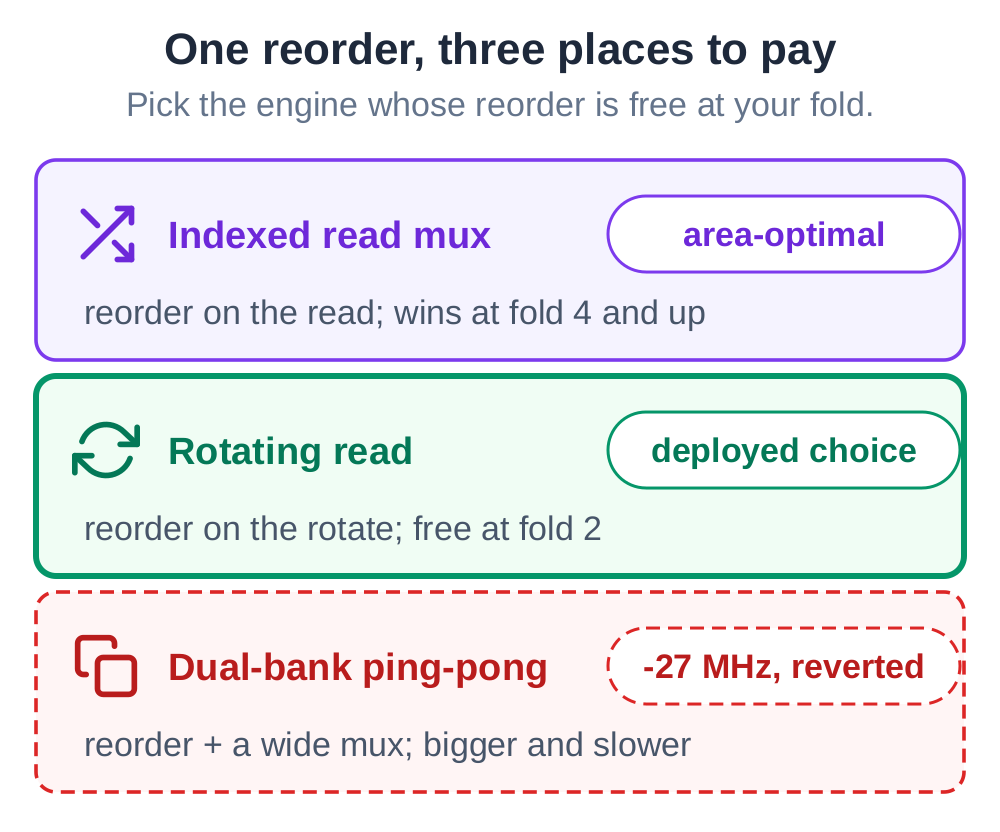
The problem was not folding. It was how that read was built, and a different build brings the clock back.
AI swaps in the right micro-architecture
AI changed the read to a rotating one: read a tap that never moves, and let the bank rotate by one window each phase to present the next slice. The phase counter leaves the wide read path and only selects the branch metric. AI re-measured: at the same fold of 2, the clock rose from 147 to about 160 MHz, at flat logic and a few fewer flip-flops.
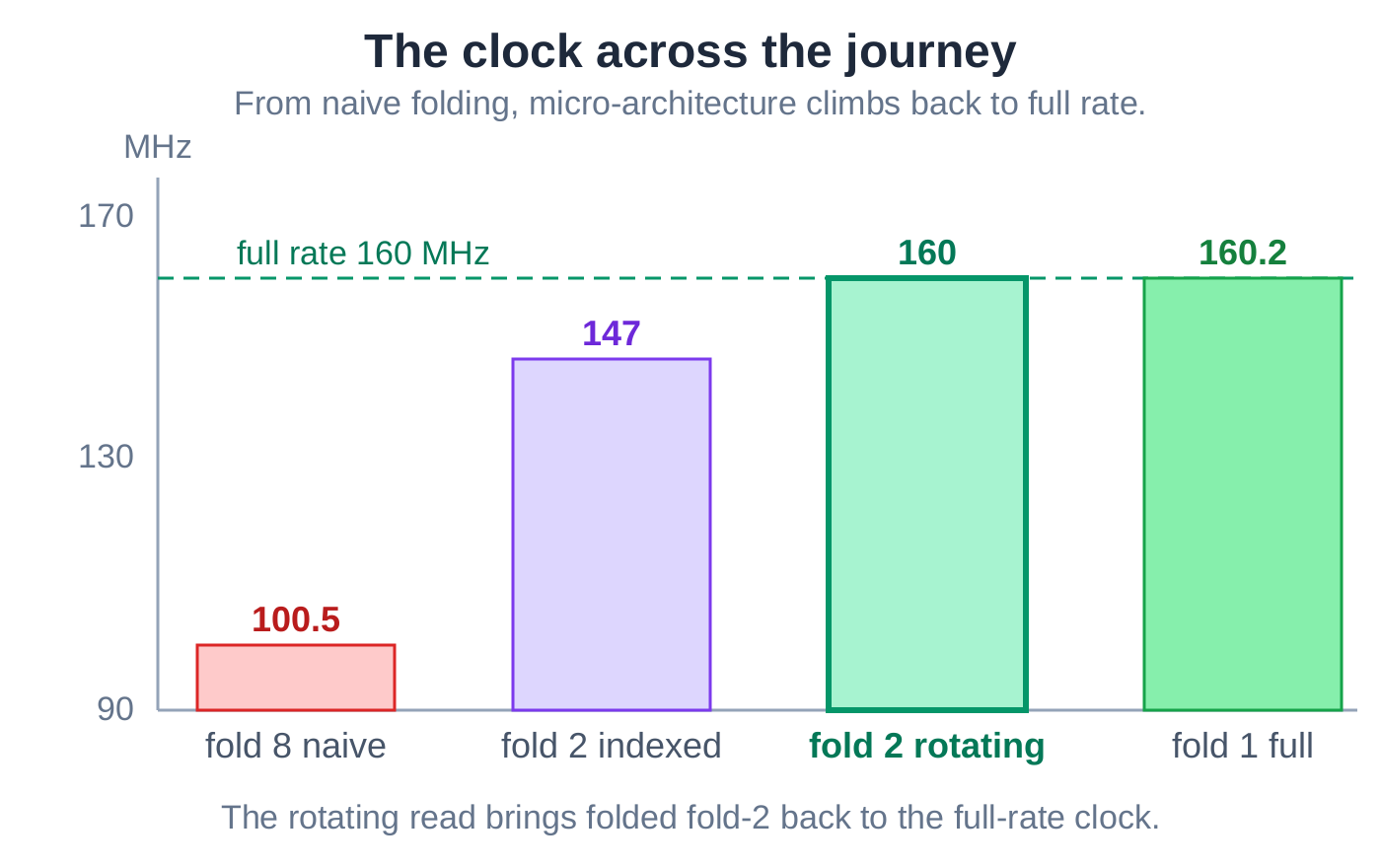
There is a general principle behind it. Folding any two-input butterfly forces a data reorder that cannot be avoided. The only choice is where you pay for it, and AI placed it where it is free.
AI applies more resource levers
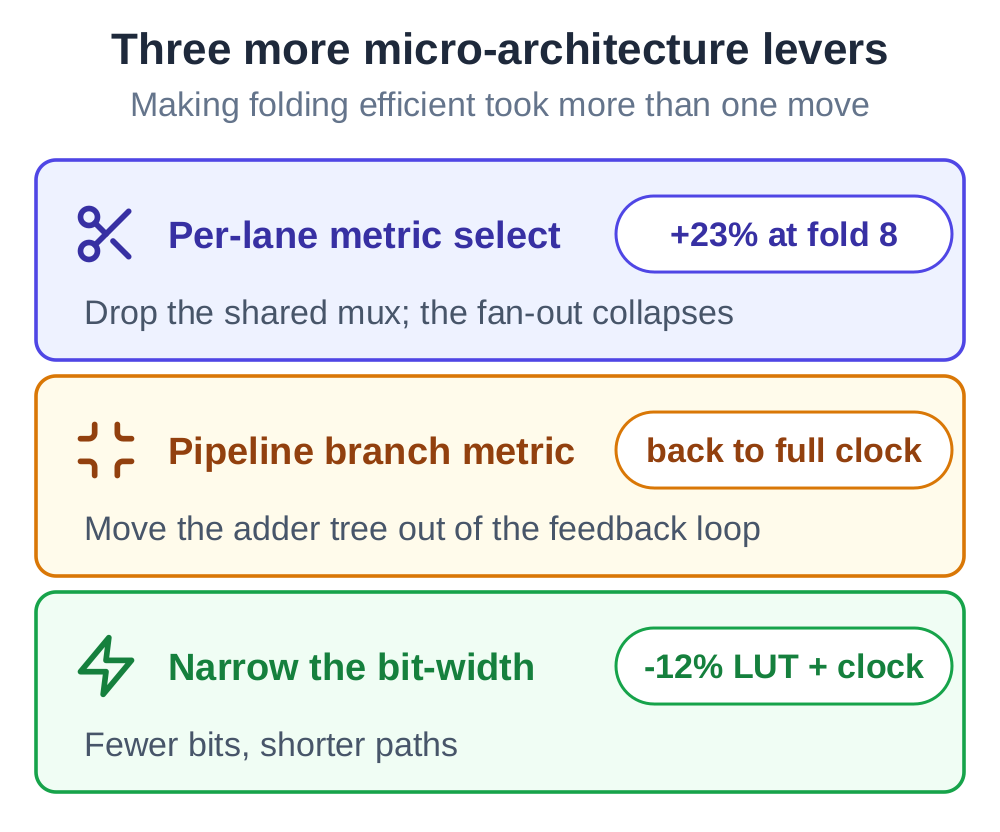
Making folding efficient took more than one move; it took a string of micro-architecture choices AI worked through: a per-lane metric select that collapses the fan-out (worth +23% at the deepest fold on the lower rates); pipelining the branch metric out of the feedback loop (deep rates back to full clock); and narrowing the internal number formats, which on the lower code rates saves more area than folding and raises the clock at the same time.
AI also backs out of a dead end
AI tried a third option too: a dual-bank ping-pong. It was built, synthesized, placed and routed, not just sketched. It came back bigger and about 27 MHz slower than the rotating read, so AI reverted it. That negative result was worth having: it is what made the win credible. Here AI behaves like an engineer, not a code generator.
A resource menu, deployed in a real receiver
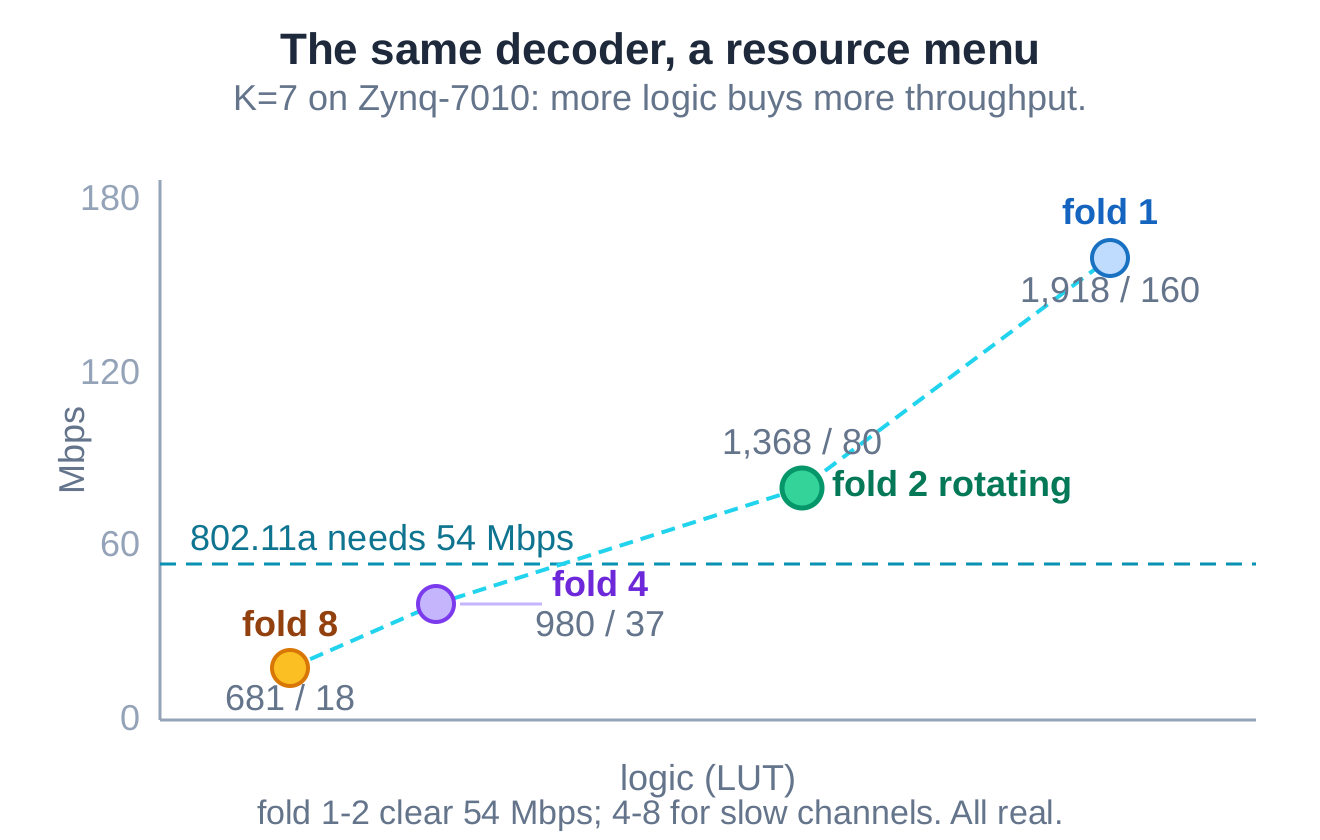
What AI produced is not a single point but a whole resource menu: shallower fold is faster and larger, deeper fold is slower and tiny. 802.11a's 54 Mbps is cleared by fold 1 and fold 2; fold 4 and fold 8 are smaller and slower, for slow channels you can pack several onto one device. Every point is verified.
The deployed fold-2 decoder was dropped into a complete 802.11a receiver and fed raw samples; across all eight modulation and coding schemes it recovered the payload with zero bit errors.
This is how you apply AI to resource optimization
The deployed result is small and exact: a fold-2 decoder that kept a full engine's clock at a folded engine's area, on a low-cost Zynq-7010, at 1,368 LUT and zero DSP. The loop carries further than the decoder. AI read the physical constraints and told a folding problem from a micro-architecture one. It placed the unavoidable reorder where it is free. It built, measured and reverted a dead end. And it proved every change bit-for-bit against the reference. The reusable result is that loop, not the one decoder.
For the full technical detail (the RTL micro-architecture diagrams, the measured fold, clock and resource tables across constraint lengths and code rates, and the verification chain) see the technical report.